Portfolio: Jobson
A webserver + UI that turns command-line applications into a job system.
[server github] [ui github] [docs] [live demo]
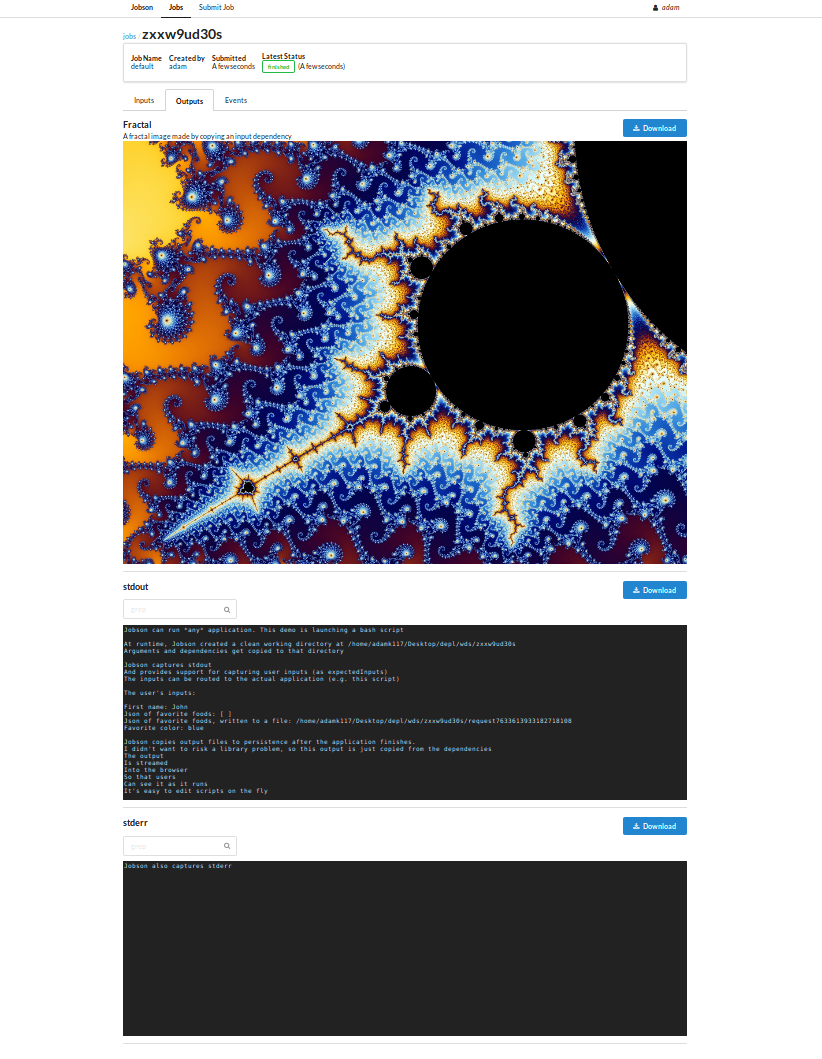
Demo
Key Points
- Developed to tackle real-world problems Gaia developers faced
- Frontend developed with SemanticUI (styling), React + Javascript
(code), and Webpack (build).
- Frontend entirely separate from server project.
- Backend developed with Dropwizard (web framework), Java, Maven
(build). Uses process forking to run jobs
- Typical requests are 1-100 MiB, because some queries can be for
millions of stars.
- Typical results sets are 0.5-20 GiB
- Typical jobs use python scripts to run Hadoop + Spark applications
- Running in production for around 1 yr (as of Jul 2018) with minimal
breaking changes
- Still under active development. Used by other teams.
Problem Statement
- Gaia scientists depend on up-to-date satellite data to conduct their
research
- The applications that extract the data they need are complex, change
frequently, and require many dependencies. Only specialist
developers can realistically can run them. Executing the request is
a time drain on the developers. Manual execution can be
inconsistent.
Other Considerations
- Data requests can be large. For example, a typical request may
include > 5 million IDs to retrieve from (e.g.) a Hadoop cluster
- The resulting datasets can be large (1-100 GiB). Server must be able
to handle this
- Because the underlying jobs are quite different (e.g Java, Bash,
Python), the system needs to be configurable
- Jobs will need to run on remote clusters (e.g. Hadoop/Spark)
Jobson’s Approach
- Make the UI flexible enough to automatically generate
inputs/outputs on-demand.
- Make the server’s API configuration-driven: developers write a job
spec in YAML, which the server uses to generate the API. This means
no code needs to be written when a new job needs to be hosted.
- Leverage the power of the operating system to do the actual
execution. Jobson forks off a separate process for each job, which
means jobs can be written in entirely different programming
languages and work fine.
- Use simple data structures for configuration and persistence. Each
job is persisted as a bunch of simple files in
jobs/, each spec is
persisted as a bunch of files in specs/.
