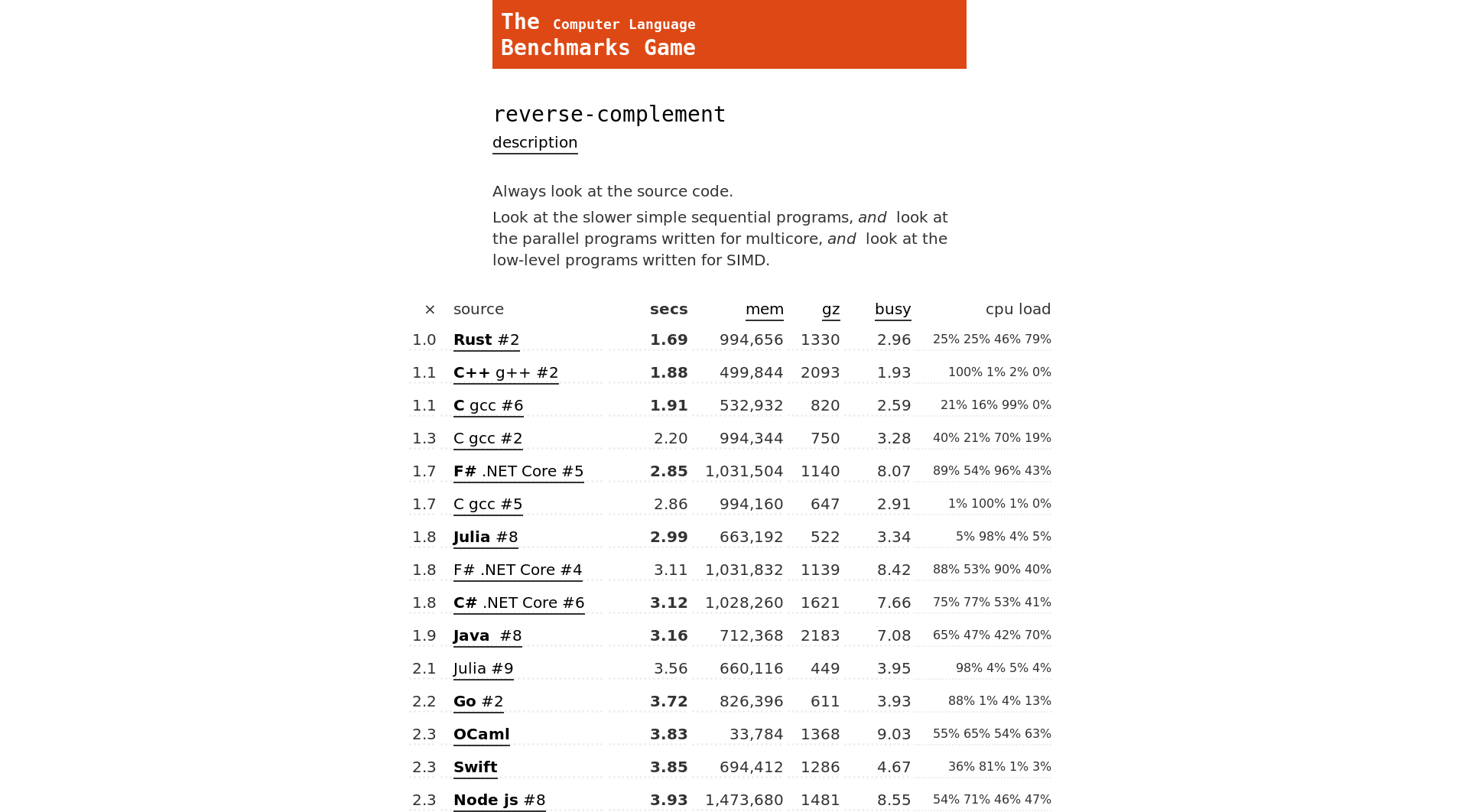
So my latest interest has been trying to squeeze performance out of simple algorithms - mostly so I can understand the impact of branch misses, lookup strategies, etc.
I spent Sunday writing an optimized solution to the language
benchmark
game’s
reverse-complement
challenge. I ended up doing all kinds of hacky things I’d never
recommend doing in prod, like writing a custom vector and writing
tricksy algorithms. Repo
here, submission
here.
Well, for all my hard work, I managed to come… Second! To, of
course, a much tidier Rust implementation (❤️). Why? Not because the
Rust solution is a more efficient (it’s not: it takes at least 2x
more cycles and memory than my single-threaded C++ implementation),
but because the the Rust implementation throws threads at the problem,
which is the true power of Rust (in addition to the fact that the Rust
version can be just as efficient as the C++ one by adding some SIMD
and unsafe code).
This kind of underlines an important trend that’s likely to shape software development over the next decade or so: processors aren’t getting faster, but they are getting more cores. This means that there is an upper limit on how fast single-threaded software can get in the future. Rust has the dual advantage of being extremely fast and easy to multithread. It’s well-positioned for the future. All we need to wait for is when IT departments around the world start realizing how much it’s costing them to scale-out their ruby webapps ;)