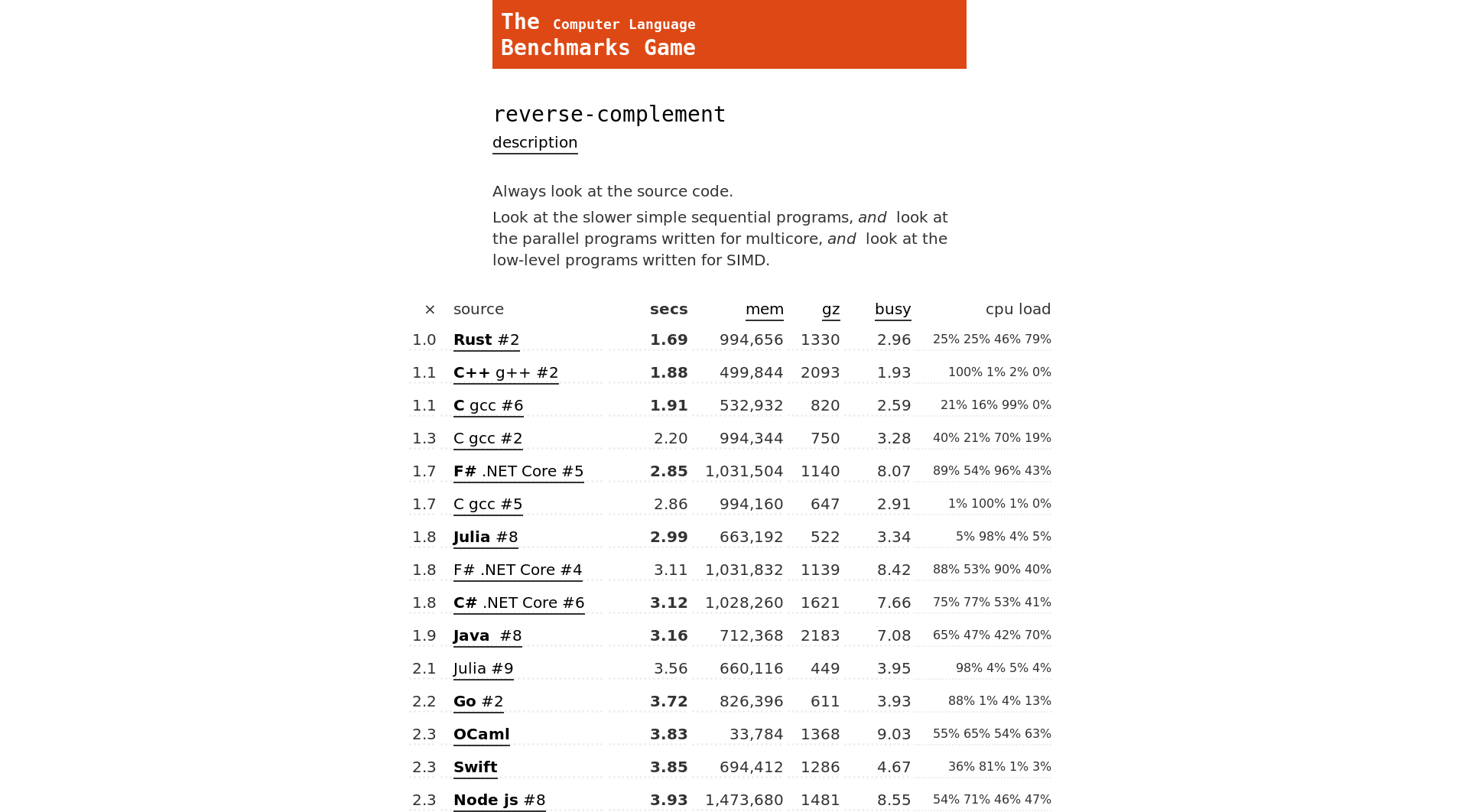
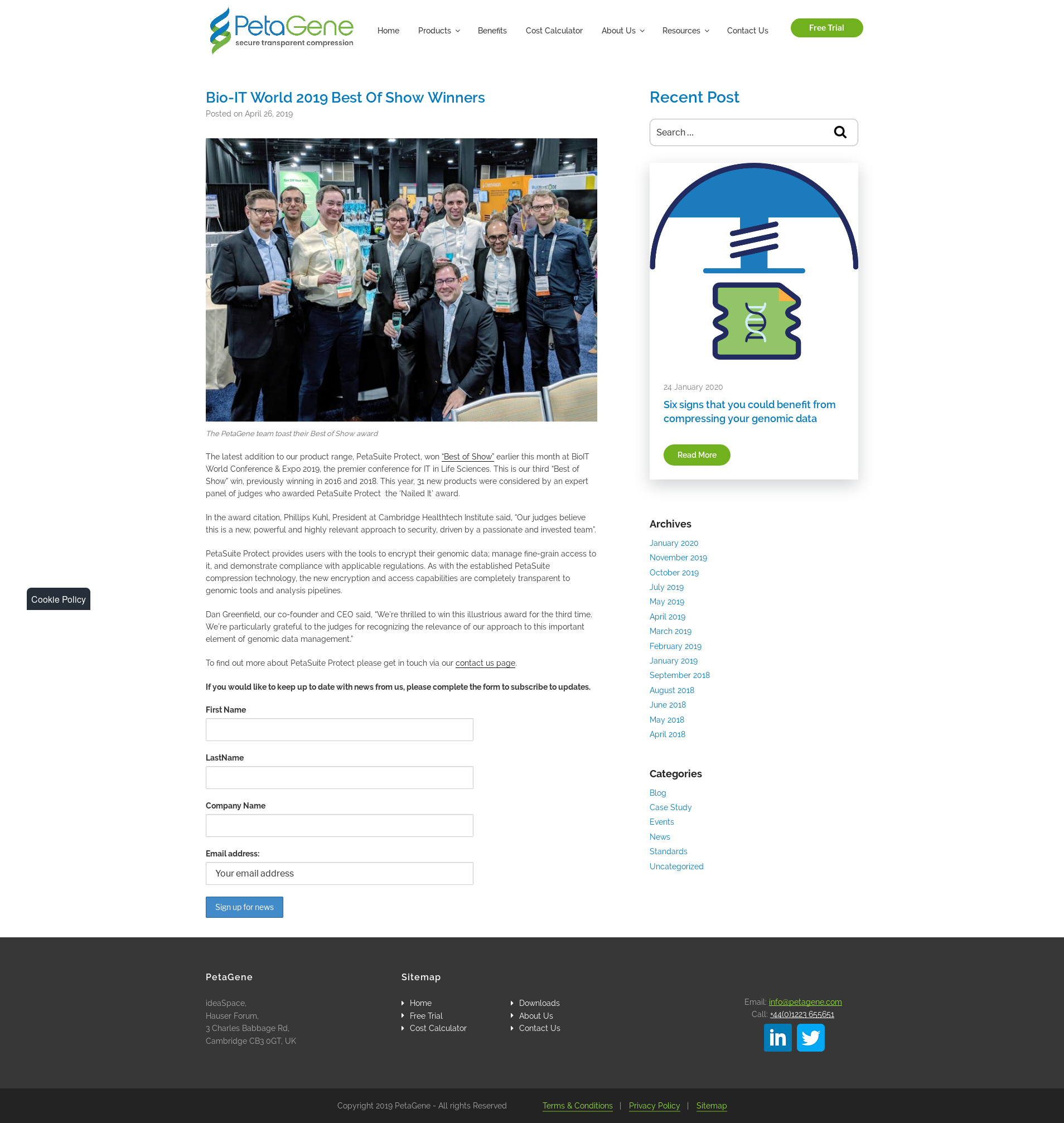
Yay, I have a new job! I’m now an Open-Source Software Developer at TU Delft, where I’m going to be working on biomechanical simulation software.
Why do I mention this? Because I’m initially tasked with trying to make OpenSim faster, which is something that beautifully ties together a few of my loves (research software, systems development, and low-level perf optimizations) with a few of my hates (software written by researchers, C++, and diagnosing cache misses) and I’ve been wanting to learn+write about performance for a while.